

Techniek speelt een steeds grotere rol in alle aspecten van ons leven. De discussie over de kwalijke aspecten wordt momenteel overal en door iedereen gevoerd. Maar zelfs de experts verschillen van mening over de vraag of we al reddeloos verloren zijn, of dat er nog een oplossing te verwachten is.
Een volledige oplossing lijkt nog ver weg, maar tot die tijd is het zinvol om wel alvast stappen te zetten om bepaalde oorzaken van de problematiek aan te pakken.
In de tekst hieronder wordt geschetst hoe “Do-It-Yourself AI” een oplossingsrichting is voor twee problemen die momenteel spelen.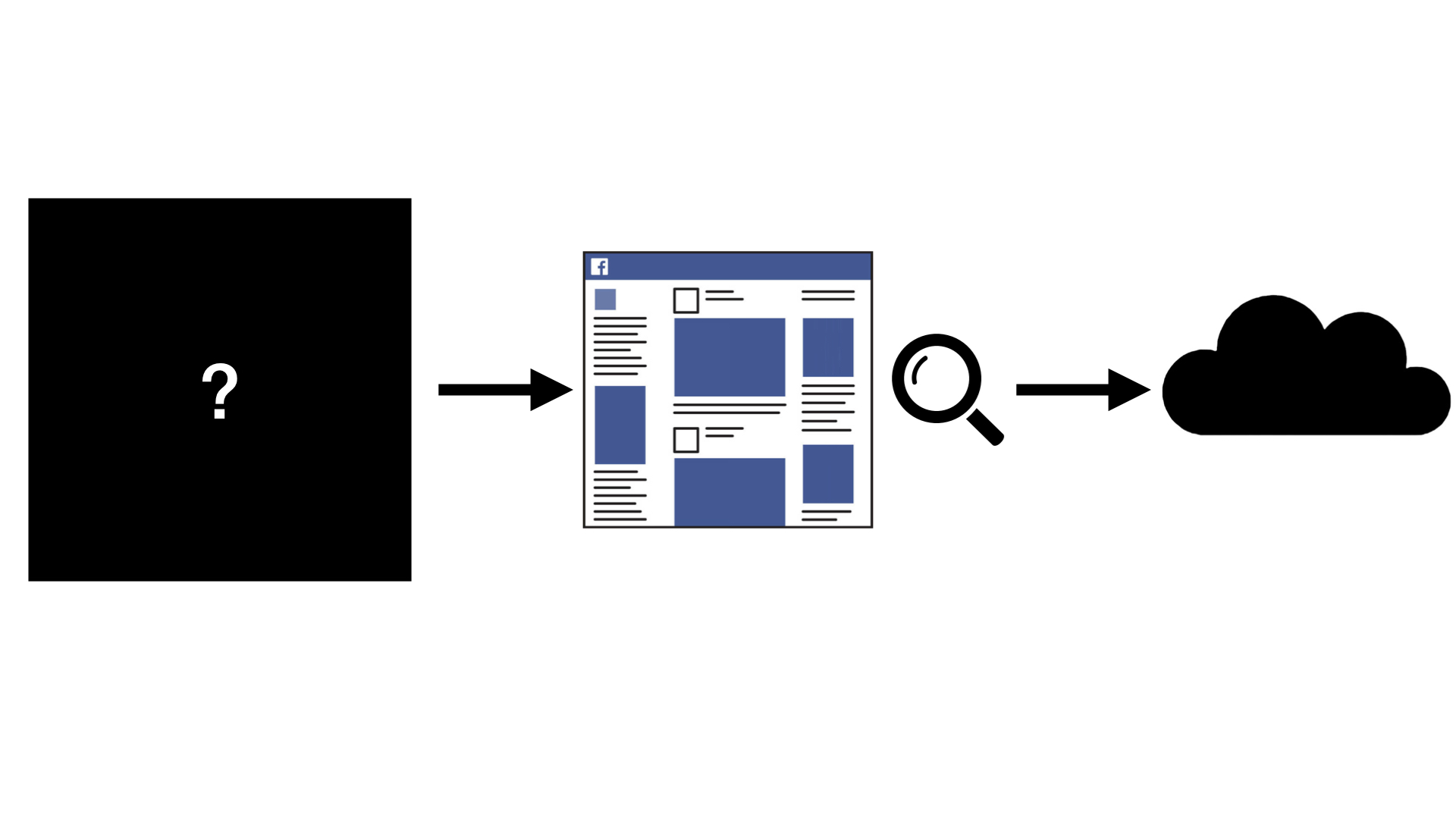
Een groeiend aantal mensen maakt zich zorgen over de dubieuze aspecten van social media. Hoe manipuleren partijen zoals Facebook ons? Hoe nauwkeurig worden we geobserveerd, waar komt de data terecht en hoe ziet ons profiel er daar uit?
Nog een zorgelijke ontwikkeling is de robotisering. Worden we straks overbodig als robots al ons werk gaan doen? Geen zorgen, we gaan niet stil zitten. Wij nemen de positie van de robots in. En dat is wel zorgelijk.

De twee zorgen krijgen met elkaar te maken door de ontwikkelingen op het gebied van Augmented Reality brillen. Alle tech-bedrijven zijn daar druk mee bezig, ook Facebook. Maar wat als we de wereld aanschouwen door de bril van Facebook?

Wat dienen we te ervaren als een handigheid, en wat komt neer op manipulatie? In het voorbeeld hierboven een date. Vooralsnog erg onrealistisch dat je op date gaat met zo’n bril, maar de brillen worden compacter en comfortabeler.

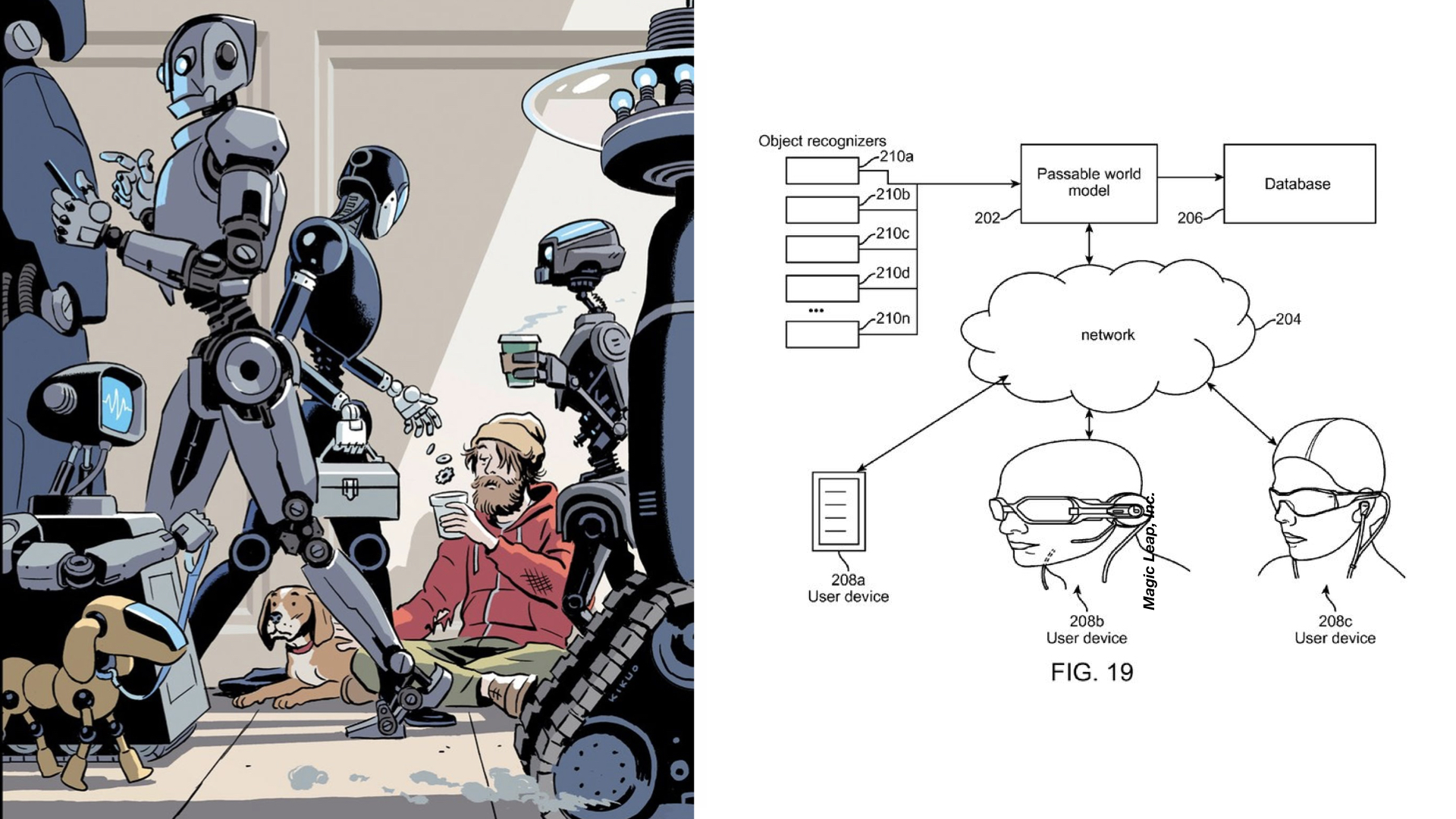
Het leek alsof de AR bril succesvol was verslagen doordat de maatschappij zich massaal tegen Google Glass had gekeerd. Maar het blijkt een zevenkoppig monster.

Talloze tech-bedrijven zijn druk bezig nieuwe versies te maken en die worden beter, subtieler en krijgen een betere batterij. Je kunt ze de gehele dag op hebben, zonder dat de omgeving dat door heeft en daar aanstoot aan neemt.
Grote kans dat de toekomstige mens rondloopt met een HUD, een Heads Up Display. De hele dag door meldingen waar je niet aan kunt ontkomen. Een beetje zoals op onze smartphone, maar dan in-your-face.

Als we de AR bril net zo obsessief gaan gebruiken als onze telefoon nu, dan ontstaat een ongekende versnelling van de hoeveelheid data die we uit gaan wisselen met de cloud.
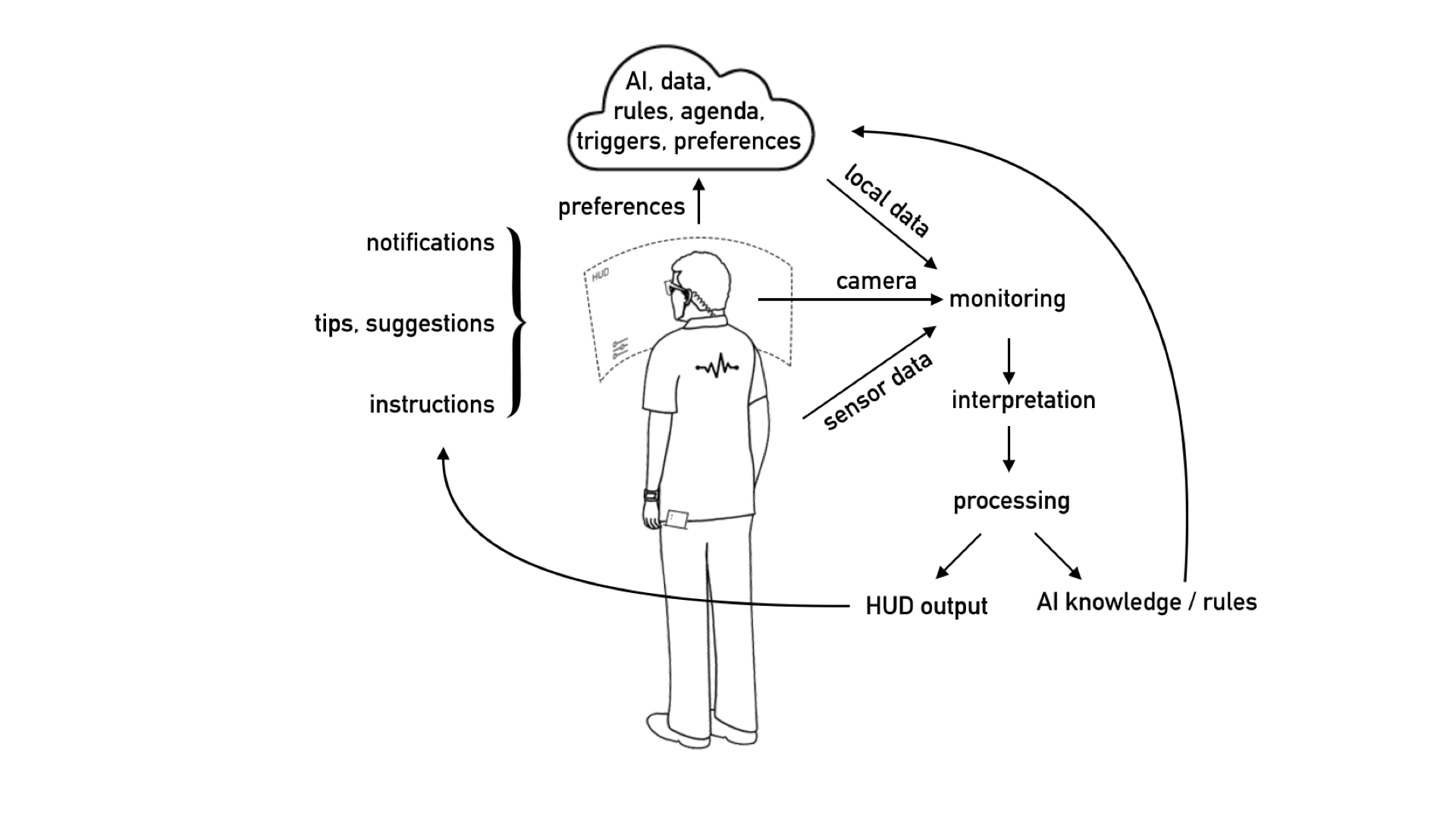
We blijven de bril op ons neus houden zolang die goed functioneert. Het apparaat krijgt alle kans om permanent met ons mee te kijken, alles observerend met object recognition. Met AI in de cloud gaat de bril ons steeds beter kennen, zodat de gebruikservaring ook steeds prettiger wordt. We zetten het apparaat niet meer af.
We hebben nog de keuze om de monitoring uit te schakelen. Maar het is een schijnkeuze. Het apparaat verleid ons de permissies te verstrekken met de mededeling dat alleen met nog meer data de service echt goed kan zijn. (Of we maken de keuze niet eens bewust, uit haast, gemakzucht of onkunde).
Dankzij GDPR wetgeving weten we officieel wel waar onze data blijft. Maar helaas zijn er loopholes. Met name de afgeleide data die wordt gecreëerd na bestudering van de data over onze bezigheden en voorkeuren, daar krijgen we geen inzicht in.
We raken volledig overgeleverd aan de cloud. Meerdere clouds zelfs. Elke stuk hardware of software is aan het proberen een zo goed mogelijk profiel van ons op te bouwen.

Het zijn de usual suspects. Er zou nog hoop zijn als er een alternatieve optie zou zijn. Maar ….
Maar zelfs onderling gaat het twijfelachtig zijn of meerdere cloud diensten elkaar gaan verdragen. Vermoedelijk wordt het een concurrentiestrijd om het alleenrecht die zich weer via ons zal afspelen.
Het is de vraag of het goed komt als we niet ingrijpen. Zelfs al gaan er filosofen aanschuiven bij de bedrijven om de ethische kwesties aan te stippen, een echte radicale verandering zal niet op treden, en die is wel nodig. Er is maar één oplossing die echt werkt om big-tech niet langer machtiger en invloedrijker laten worden: alles weer naar onszelf toe trekken.
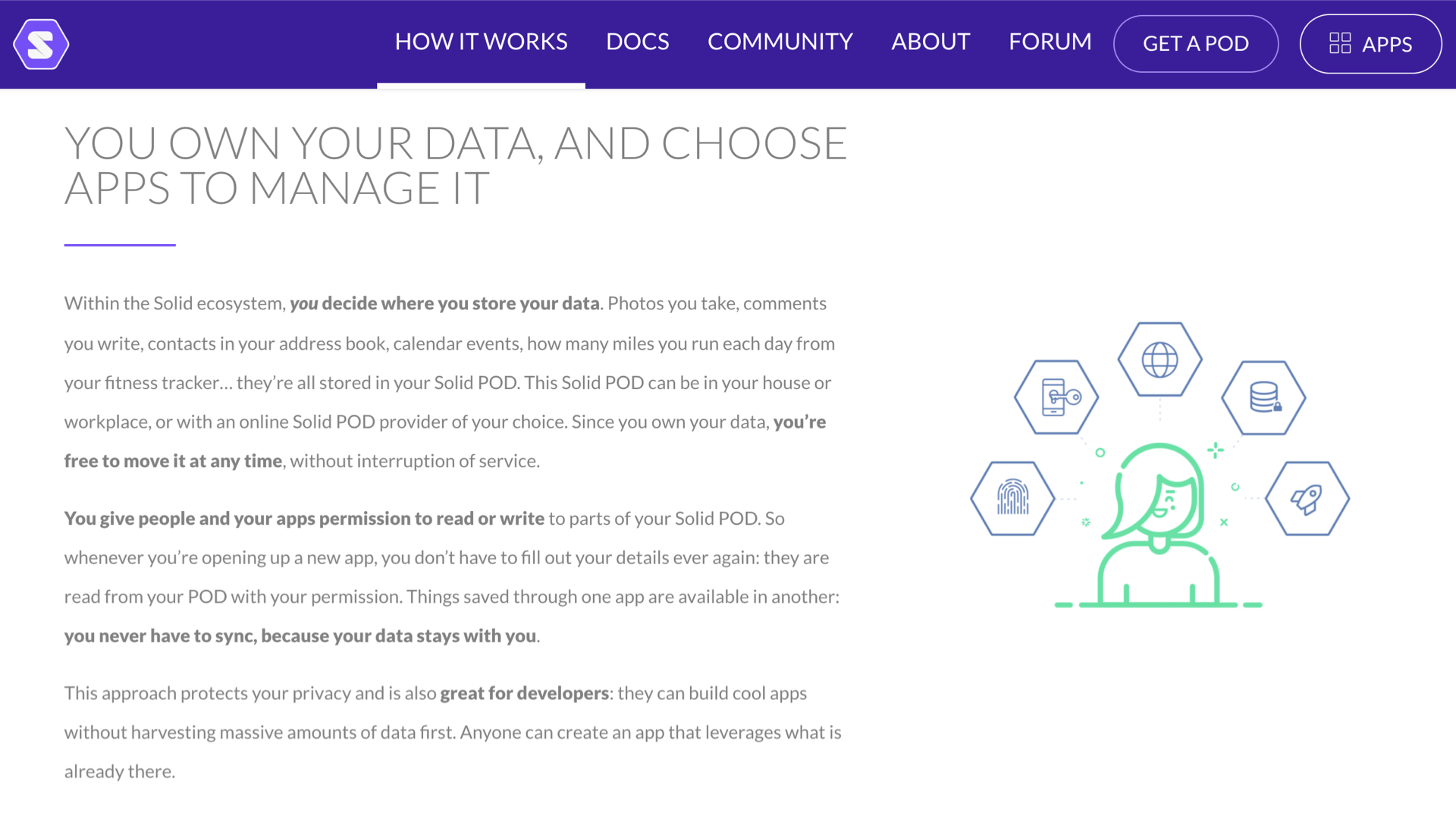
Het aantal initiatieven om die wens nader invulling mee te geven neemt toe. Bijvoorbeeld het Nederlandse #IRMA en Solid van Tim Berners-Lee, de uitvinder van het World Wide Web. Eensgezind is men dat er ‘data kluisjes’ nodig zijn waarin je weer zelf eigenaar wordt van je eigen data en bepaalt wie er wanneer bij kan.
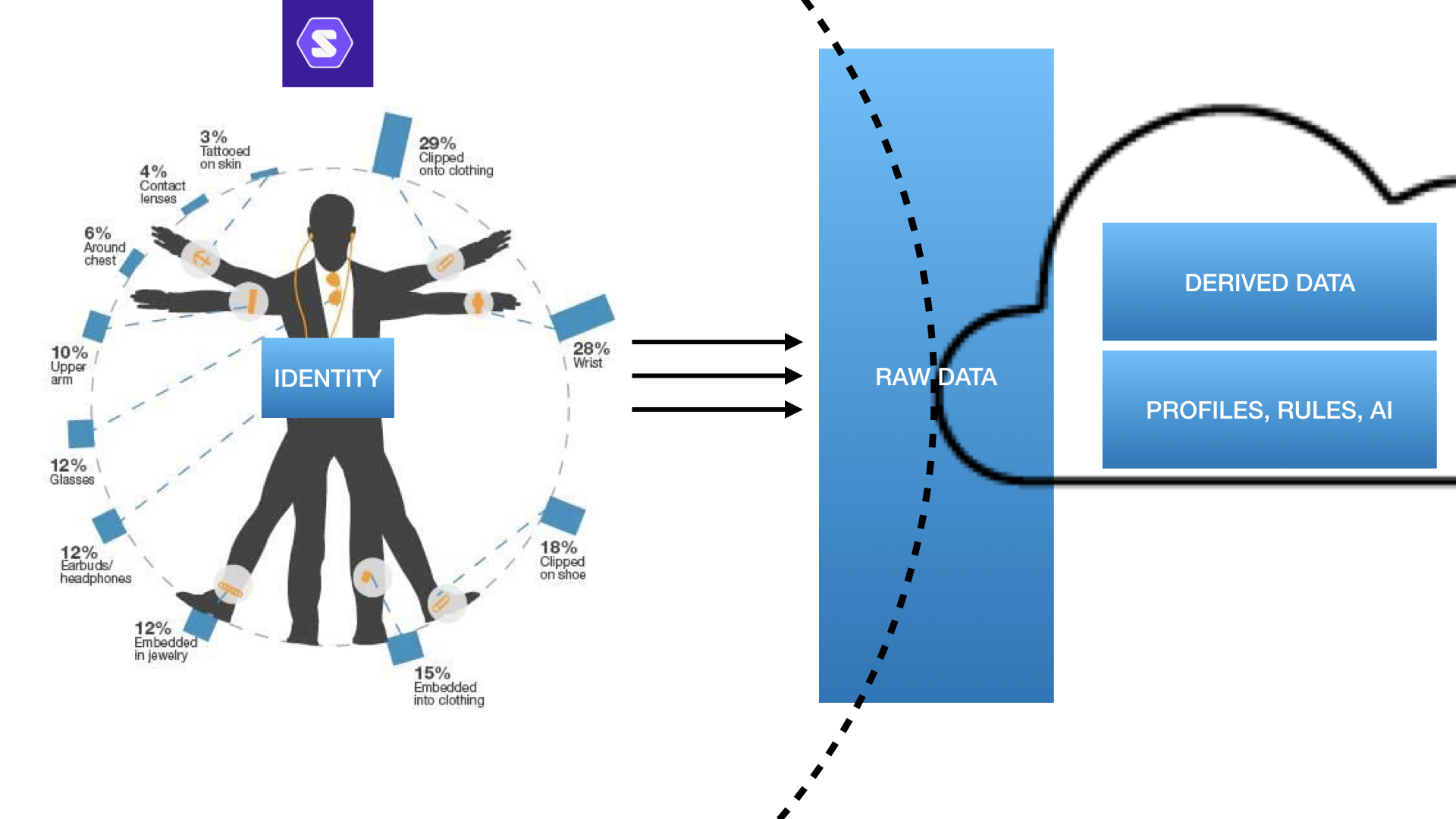
In veel van de voorbeelden die worden gegeven wordt toegelicht hoe je je persoonlijke data kunt beschermen. Maar het is belangrijk dat ook het hele ecosysteem aan apps mee gaat in deze opzet. Met name is het van belang dat afgeleide ‘derived’ data niet ontstaat in een externe cloud, maar dat ook die data binnen de eigen datakluis terecht komt.
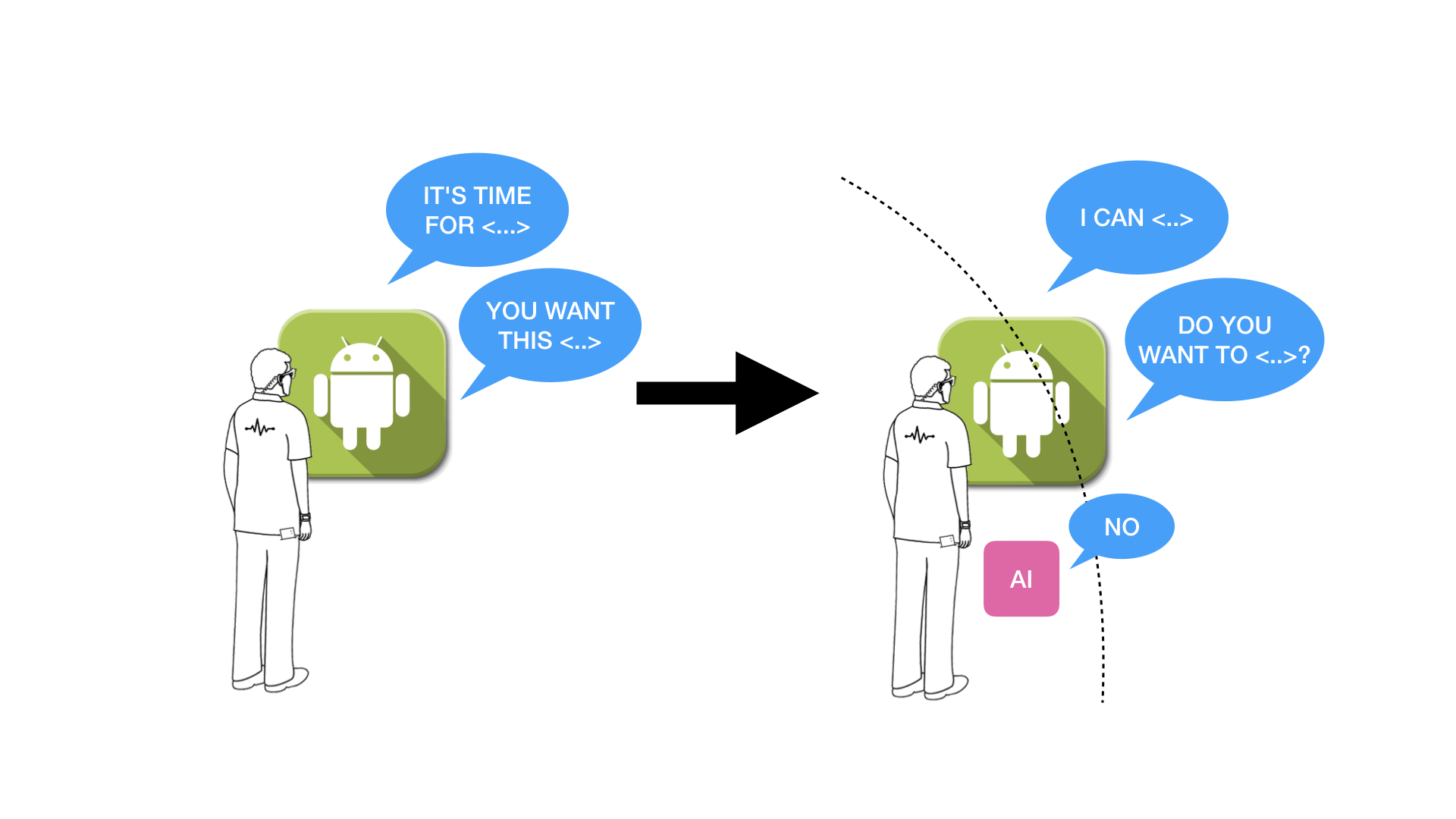 Apps bereiken je dan niet langer ongevraagd en pro-actief omdat ze via monitoring weten wanneer je behoefte aan iets hebt. Die kennis hebben ze niet meer. De dynamiek wordt anders. Een app kondigt nog wel aan welke diensten er voor je zijn, maar zelf bepaal je of je daar wel of niet op in gaat. De interactie met apps gaat verlopen via een “API“, een Application Programmers Interface en biedt voordelen én nieuwe mogelijkheden.
Apps bereiken je dan niet langer ongevraagd en pro-actief omdat ze via monitoring weten wanneer je behoefte aan iets hebt. Die kennis hebben ze niet meer. De dynamiek wordt anders. Een app kondigt nog wel aan welke diensten er voor je zijn, maar zelf bepaal je of je daar wel of niet op in gaat. De interactie met apps gaat verlopen via een “API“, een Application Programmers Interface en biedt voordelen én nieuwe mogelijkheden.
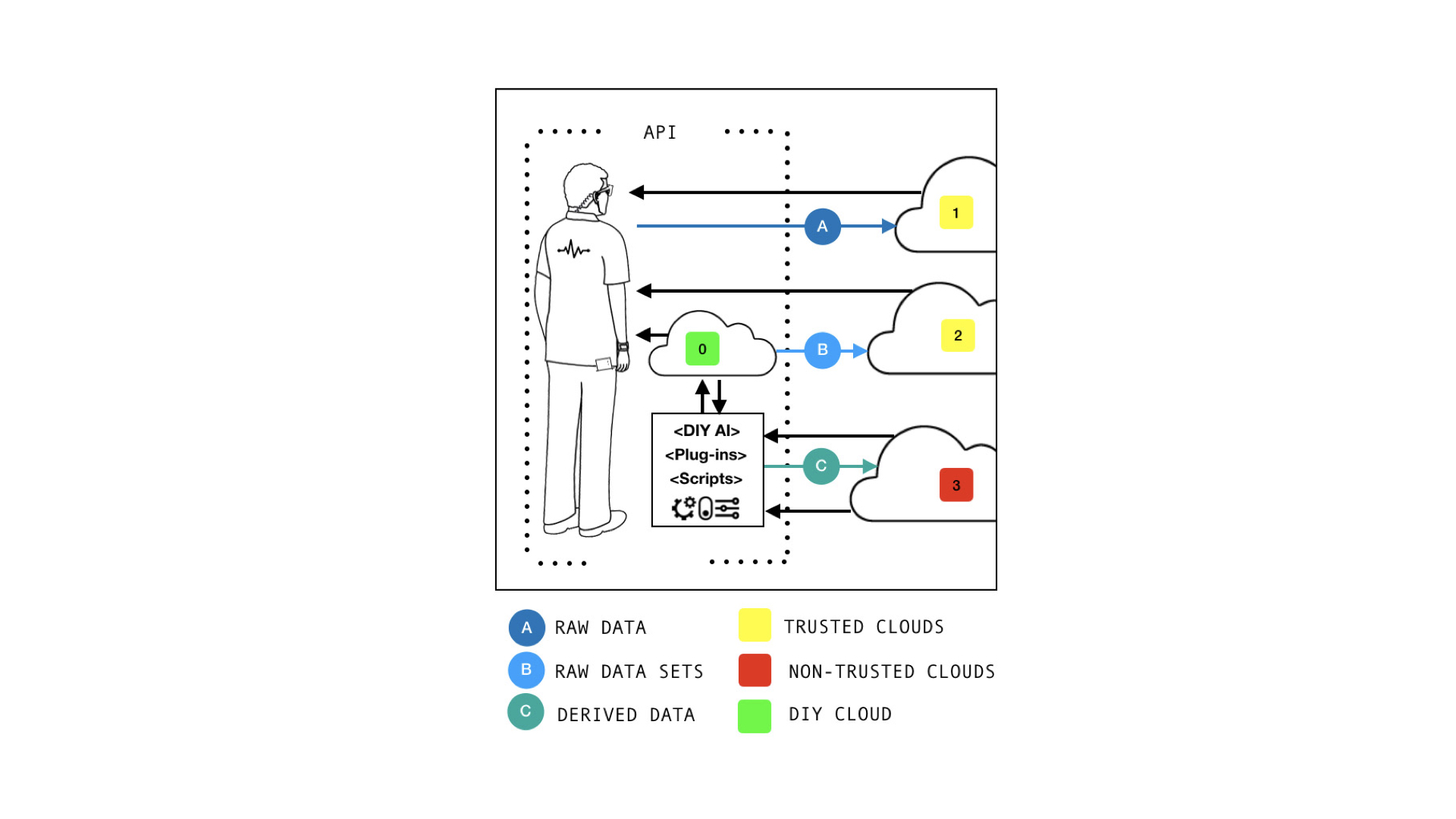 Kiezen welke functies je door welke cloud laat uitvoeren wordt een bewuste keuze. Clouds kunnen zich differentiëren op meer dan alleen maar de geboden functionaliteit. Transparantie wordt een factor die bepaalt of je een cloud wel of niet voor een bepaald doel gebruikt. Vertrouwde clouds krijgen rechtstreeks toegang tot je data. Een cloud waarvoor dat niet geldt, krijgt enkel inzicht in actuele afgeleide data. Zo’n cloud kan wel opvragen en vernemen of je op een bepaald moment in de stemming bent voor een dienst, maar niet de reden waarom. Dat wordt bepaald door je eigen software die zich baseert op data in je lokale cloud. Eigen data wordt daarin verzameld om middels Do-It-Yourself AI te worden verwerkt tot een of meerdere eigen profielen die bestaan uit afgeleide data en regels.
Kiezen welke functies je door welke cloud laat uitvoeren wordt een bewuste keuze. Clouds kunnen zich differentiëren op meer dan alleen maar de geboden functionaliteit. Transparantie wordt een factor die bepaalt of je een cloud wel of niet voor een bepaald doel gebruikt. Vertrouwde clouds krijgen rechtstreeks toegang tot je data. Een cloud waarvoor dat niet geldt, krijgt enkel inzicht in actuele afgeleide data. Zo’n cloud kan wel opvragen en vernemen of je op een bepaald moment in de stemming bent voor een dienst, maar niet de reden waarom. Dat wordt bepaald door je eigen software die zich baseert op data in je lokale cloud. Eigen data wordt daarin verzameld om middels Do-It-Yourself AI te worden verwerkt tot een of meerdere eigen profielen die bestaan uit afgeleide data en regels.
Outsourcing van deze activiteit is ook mogelijk. Een hele data-set wordt dan verstrekt aan een krachtige maar trusted cloud dienst, die bijvoorbeeld wel voldoende inzicht en controle biedt op de verwerking. De resultaten komen niet terecht in een profiel op een externe server. De bevindingen, conclusies en regels worden teruggekoppeld om lokaal in de eigen cloud te worden opgeslagen.
Het wordt op die manier mogelijk om je eigen functioneren te verrijken door de juiste software te installeren. Dat lijkt een beetje op de situatie zoals destijds in Second Life. Een standaard avatar kon daar niets, maar in de winkels in SL was niet alleen virtuele kleding te koop, ook waren er hele bewegingsroutines en andere scripts te koop waarmee je avatar superkrachten kreeg. Als je naar de virtuele disco ging, eerst even langs een shop om de nieuwste dans-moves te kopen en te installeren.

Het is moeilijk om ons voor te stellen hoe zo’n mechanisme voor een gewoon mens zou kunnen gaan gelden. Maar om het niet enkel een abstract verhaal over de toekomst te laten zijn, is er het initiatief “Be Your Own Robot”. Met een web-app kun je alvast struinen in de app store van de toekomst waar allerlei soorten scripts te vinden zijn waarmee je jezelf als mens kunt upgraden.
De scripts werken nog niet écht, de context bestaat immers nog niet. Maar je kunt de apps al wel ‘installeren’ waarbij je ook al de juiste configuratie opties moet kiezen. Daardoor kom je hands-on alvast in aanraking met de dilemma’s die in de toekomst gaan spelen als deze situatie een realiteit is geworden.

Het draait er in deze opzet om dat je niet je hele leven compleet uitbesteed aan een externe cloud. Daar wil je veel meer regie over hebben met configuratie-opties waarmee je zelf per aspect van je leven kunt bepalen op welke manier daar Artificial Intelligence een rol in mag spelen. In sommige gevallen is onnavolgbare AI acceptabel, in andere gevallen wil je zelf scherp toezicht houden op de regels die gaan bepalen wanneer je iets wel of niet dient te doen. Dat lijkt vooralsnog een kwestie van een notificatie op je telefoon negeren, maar het wordt een andere situatie wanneer een script je iets aanbeveelt of opdraagt via je augmented reality bril, die je in de toekomst vaker en vaker op hebt.

Als een extern systeem het idee heeft dat je happy bent, en je als gevolg daarvan zodanig behandeld wordt, waar is dat dan op gebaseerd? Vertrouw je erop dat een systeem autonoom de juiste regels over je heeft opgesteld? Misschien is het beter om zelf de verantwoordelijkheid te nemen voor je eigen regels, en die vanaf scratch op te stellen zodat je zelf goed het overzicht behoudt. Met de “IF this THEN I” web-app kun je eens ervaren tot wat zoiets kan leiden.
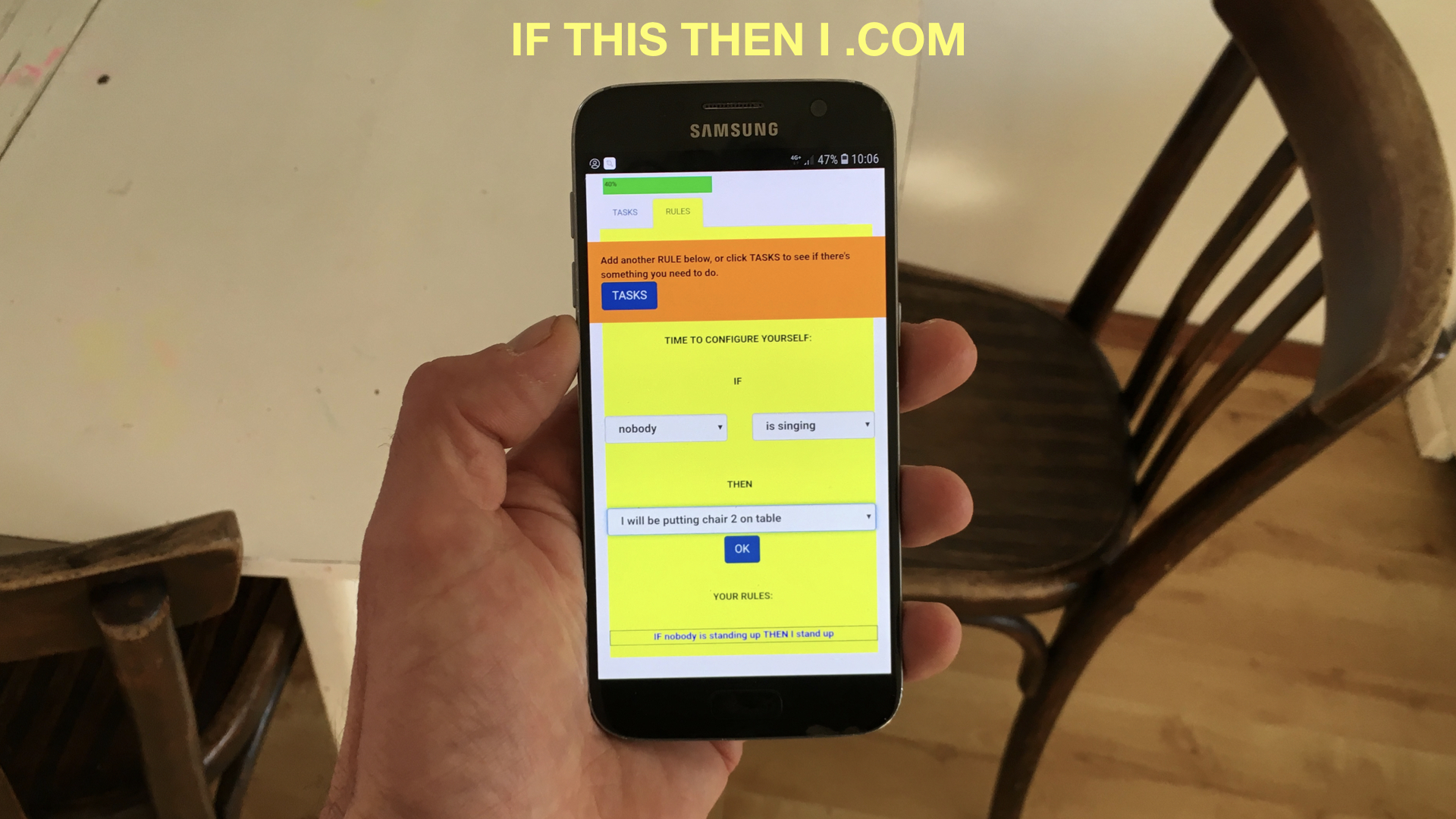 Met een aantal regels die onderling samenhangen, volgt als snel een dynamische situatie die een eigen leven gaat leiden.
Met een aantal regels die onderling samenhangen, volgt als snel een dynamische situatie die een eigen leven gaat leiden.  Maar je hele leven op die manier scripten is ondoenlijk. In specifieke situaties zou het fijner zijn om toch een AI systeem in te zetten. En voor sommige gevallen kan het ook de voorkeur hebben om helemaal geen inmenging van een computer script te hebben.
Maar je hele leven op die manier scripten is ondoenlijk. In specifieke situaties zou het fijner zijn om toch een AI systeem in te zetten. En voor sommige gevallen kan het ook de voorkeur hebben om helemaal geen inmenging van een computer script te hebben.
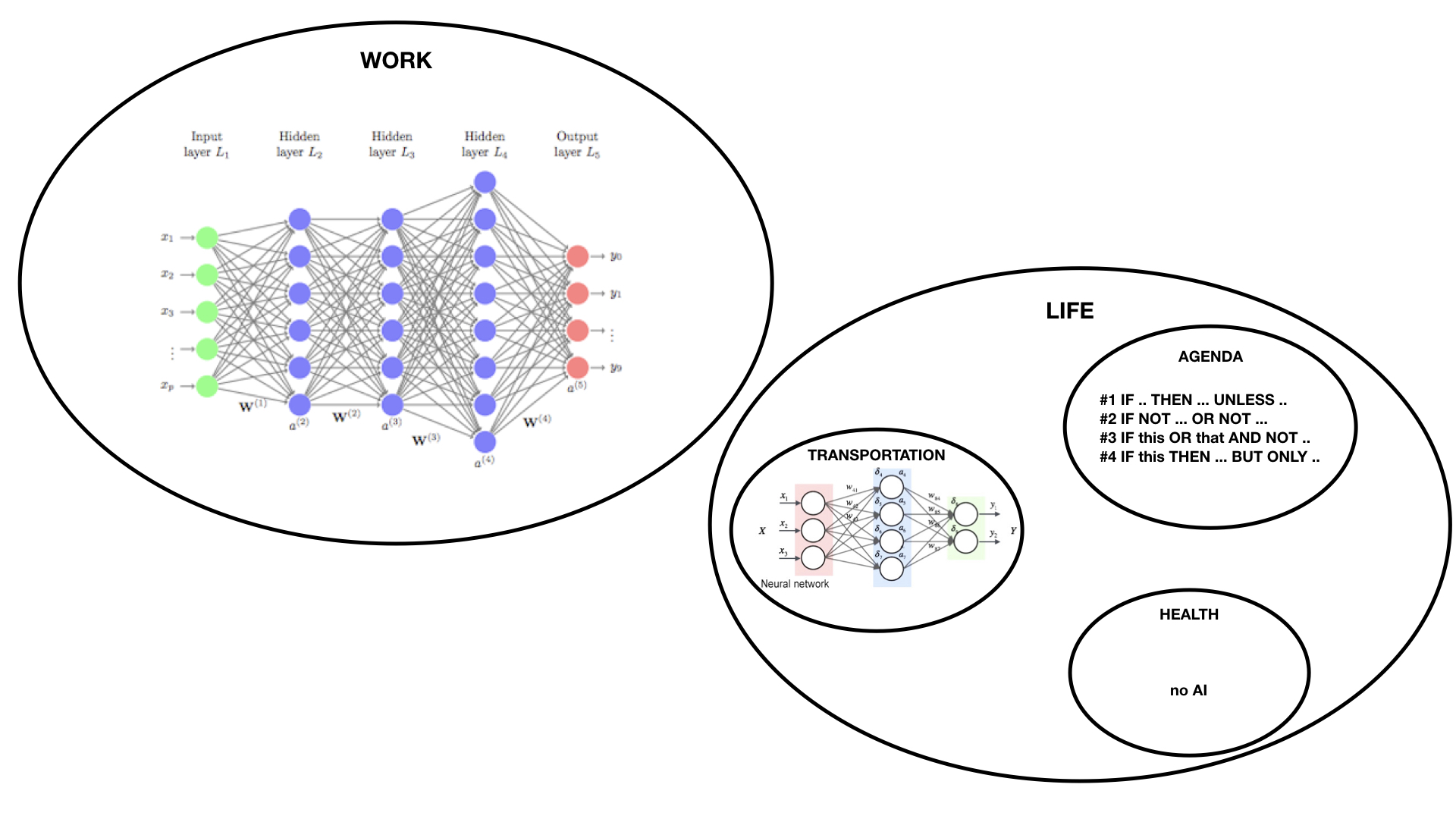
Om hier de juiste keuzes in te maken, kan het nodig zijn zelf wat meer inzicht te krijgen in de werking van AI. Dat betekent niet dat ieder individu z’n eigen AI software moet implementeren. Die bestaat al, en het prettige van bepaalde soorten AI is dat er eigenlijk geen complexe logica opgesteld De AI categorie “Machine Learning” werkt op basis van grote data-sets waarmee een systeem automatisch wordt getraind.
De interface (zie hieronder) van dat soort software oogt ingewikkeld, maar de voornaamste taak voor een gebruiker is zorgen dat de juiste data er in gestopt wordt. Vervolgens is het een kwestie van meerdere trainings-opties uitproberen totdat resultaten acceptabel of zelfs goed genoeg zijn.
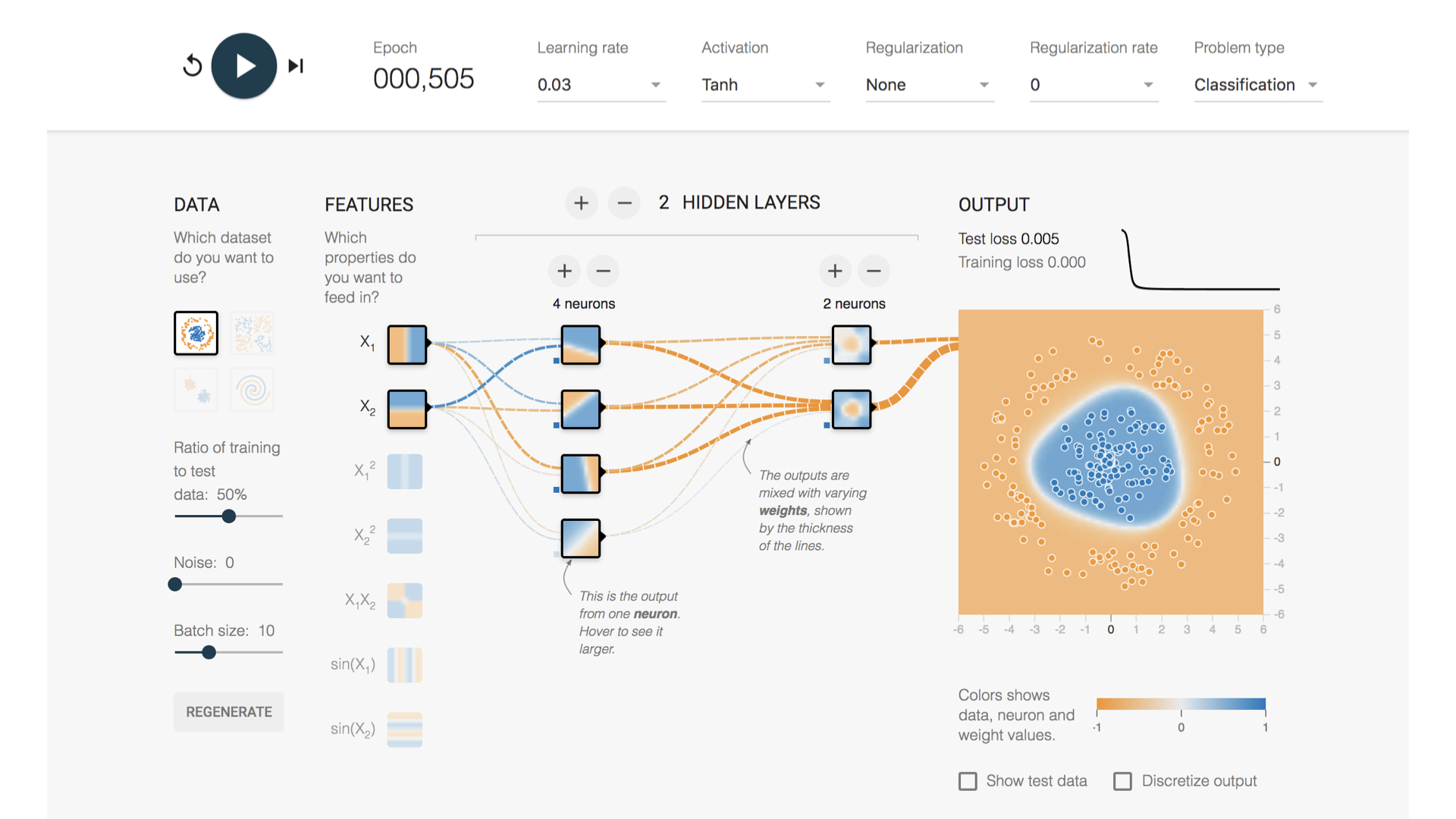
Wat de juiste resultaten zijn, moet wel helder aan te geven zijn. Een Machine Learning systeem leert zichzelf regels aan op basis van data-sets waarin duidelijk is aangegeven wat de input is en wat daarbij de juiste output is. Training levert vervolgens de juiste regels op in het tussenliggende gedeelte waarmee het systeem later zelfstandig in nieuwe situaties de juiste output kan geven.
Het heeft voordelen om zelf hands-on in de weer te gaan met je eigen Artificial Intelligence. Dat komt neer op je eigen input data verzamelen waarover je zelf aangeeft wat de juiste corresponderende output data. Je was er zelf bij, dus je kunt nog veel beter dan Google of Facebook aangeven wat je aan het doen was of hoe je voelde toen de data werd verzameld.
Met een “DIY AI” app heb je bovendien goed de controle over de momenten waarop er data ontstaat die geschikt is om toe te voegen aan een AI data-set. Zelfs kun je daarbij kiezen voor welk profiel de data-set bestemd is zodat je tegelijkertijd aan meerdere profielen over jezelf kan werken. Dat is een geheel andere situatie dan de huidige, waarin we volledig schaduwprofiel in de cloud waardoor grote tech-bedrijven ons door en door in de smiezen hebben.
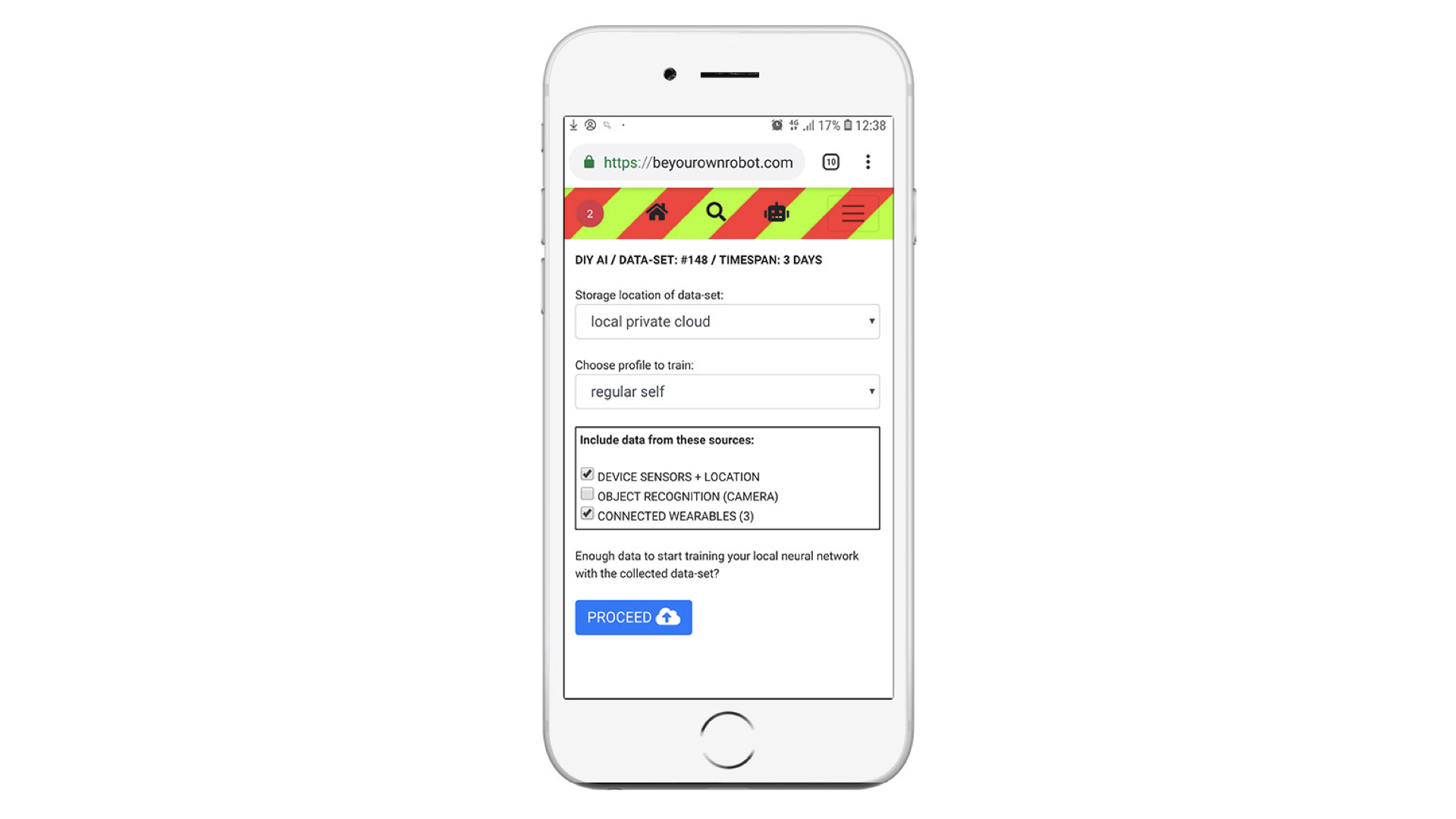
Het is tijd voor “Do-It-Yourself AI”. Dus wanneer mensen in het vervolg obsessief met hun telefoon bezig zijn, kan het ofwel Pokemon Go zijn ofwel ze zijn zichzelf even opnieuw aan het configureren.
